


Yesterday was adding the finishing touches to a marketing redesign of our screenstepslive.com site. This had been through many iterations but I felt that I finally had things the way I wanted them. ScreenSteps Live is entirely programmed in Ruby on Rails, both the web application and the marketing/sign-up area. We use Git for all of our version control.
Following standard Git practice, I was working on "marketing" branch that I had created from our "master" branch. Earlier in the day I had made a small update to the master branch to fix a small bug. In preparing to launch the updates to the marketing site I decided to do a git-rebase.
I'll go into the details of how rebase works in a second, but basically the idea is to update the changes with a child branch (marketing) with changes that have been made to the parent branch (master). I ran into a few problems with the rebase and decided to abort, which has always worked before, but not this time. At least it didn't work the way I expected it to. After aborting the rebase my marketing branch was at the same state it had been the day before. I had done a LOT of work in that 24 hour period. Basically all of my changes were gone.
Extreme panic set in. I had lost my css, my copy, my design, everything. I looked frantically for a way to recover from my disaster.
Option 1: Time Machine
Time Machine has saved me from myself more than once in my life so that was the first place I went to. Checking the backup I could see that I had a backup from about an hour ago. That was much better than losing an entire day's work, but I had still done a lot of work in that last hour. What was more, I had finished the work. There is nothing worse than having to finish something twice. So I began to look for different options.
How Git Works

To understand the problem you need to understand how Git works internally. Whenever you make a commit with Git you are taking a snapshot of how your repository looks at that moment. The commit is assigned a sha1 hash (basically, a unique id), a message and a parent. The parent is the sha1 hash of the direct ancestor of the selected commit.
A git branch really doesn't know anything more about its lineage than its direct parent. It also doesn't know anything about its children. Branches are put together by stringing together a line of parent ids.
So What Happened?
Here is how things went. Oftentimes when doing a rebase you will run into conflicts that you have to resolve before the rebase will complete. It usually isn't a big deal. But for some reason git had been acting funny because I had replaced a file titled "Movie.png" with a different image file called "Movie.png". I don't know exactly what the problem was but it caused an issue with the rebase. Instead of resolving the conflict I decided to just to git-rebase -skip for that commit. Apparently this was a bad idea.
Right after that another conflict popped up. I decided that I really didn't need to do a rebase and that this was going to be more of a pain than it was worth. I was just going to do a merge so I issued a git-rebase -abort command. The way this has always worked for me in the past is that all of the updating of the child branch with the parent branch is undone and you are right back where you started before you issued that "git-rebase master" command.
But not this time. Apparently issuing the git-rebase -skip command changed the point that my branch would rollback to, which was about 24 hours ago. Since git commits don't know anything about their children there was no way for me to "fast forward" the branch to where I needed to be.
The Solution
Even though things looked bleak I was pretty sure of one thing - Git doesn't usually delete commits from its database. That meant that my finished version was somewhere in there, I just had to find it.
I quickly searched the internet for ways to find commits that were no longer attached to a branch but didn't find anything. So then I just started digging around in the .git directory of my project.
And I found a solution.
In .git/logs/refs is a list of text files. These text files have a history of your commits and merges on a branch.
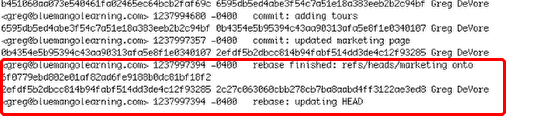
I opened up the log for my marketing branch. Above is the relevant part of the log. I have highlighted the rebase that went bad.
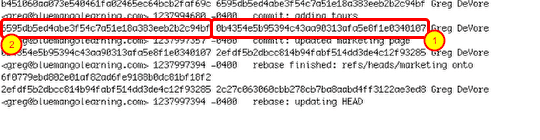
But here is the interesting part. The log lists the commit's sha1 (1) and the commit's parent (2). You can see that in the image above.
So the solution was simple:
git checkout -b marketing_recovery 0b4354e5b95394c43
This created a new branch based off of my finished marketing update (note: You don't have to enter the full sha1 hash of a branch when referencing it, just enough so that Git knows which one you are talking about).
There is one caveat: I lost the history of the branch but in this case it didn't really matter. I was just happy to have retrieved my changes.
Lesson Learned
I still don't know exactly what went wrong. It seems that git-rebase -abort should have taken me back to where I wanted to be. But I do know that I will not be using git rebase-skip again anytime soon.
